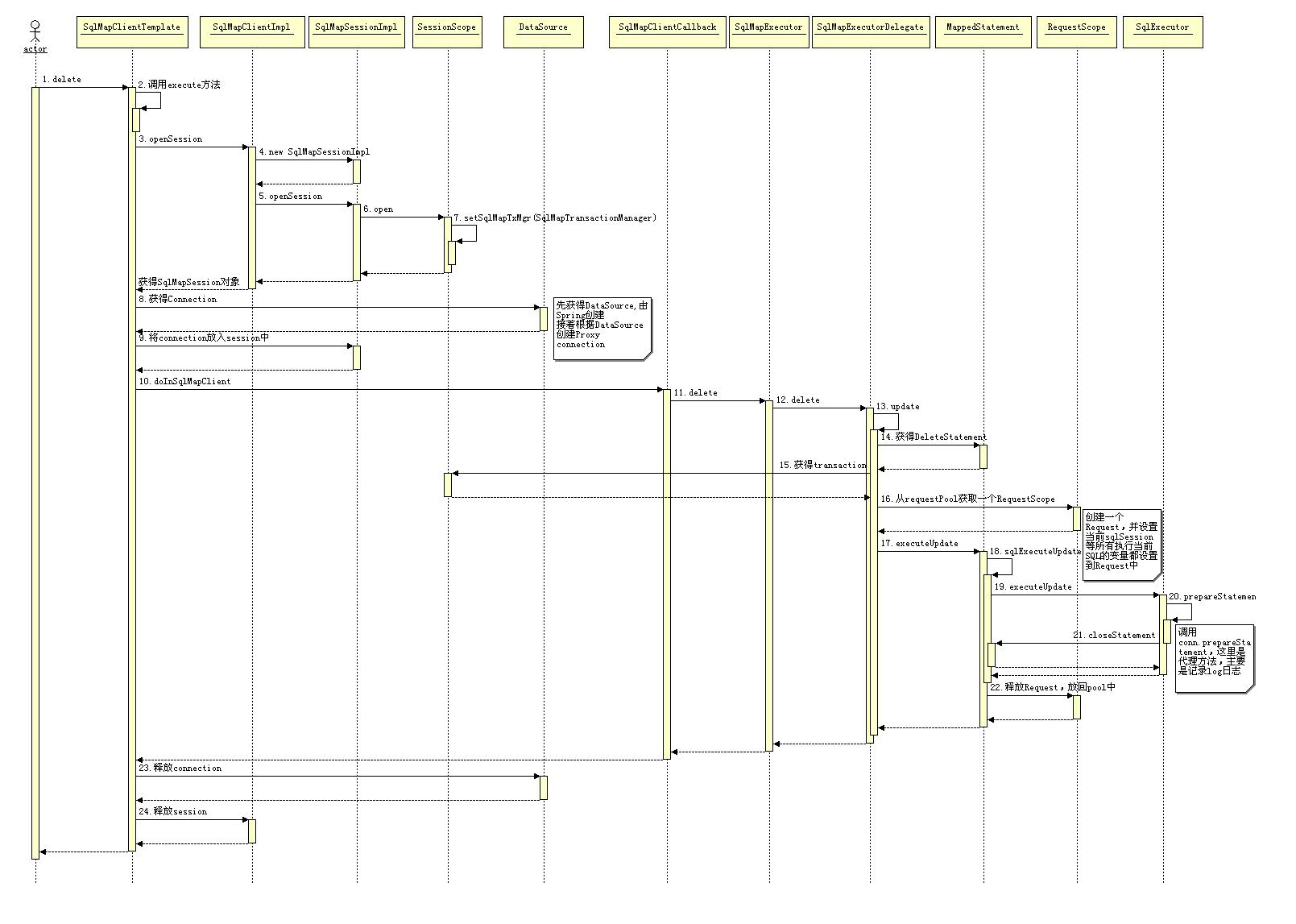
如何创建公钥
首先启动一个Git Bash窗口(非Windows用户直接打开终端)
执行:
cd ~/.ssh
如果返回“… No such file or directory”,说明没有生成过SSH Key,直接进入第4步。否则进入第3步备份!
备份:
mkdir key_backup
mv id_isa* key_backup生成新的Key:(引号内的内容替换为你自己的邮箱)
ssh-keygen -t rsa -C “[email protected]”
输出显示:
Generating public/private rsa key pair. Enter file in which to save the key
(/Users/your_user_directory/.ssh/id_rsa):直接回车,不要修改默认路劲。
Enter passphrase (empty for no passphrase):
Enter same passphrase again:设置一个密码短语,在每次远程操作之前会要求输入密码短语!闲麻烦可以直接回车,不设置。
成功:
Your identification has been saved in /Users/your_user_directory/.ssh/id_rsa.
Your public key has been saved in /Users/your_user_directory/.ssh/id_rsa.pub.
The key fingerprint is:
… …提交公钥:
6.1 找到.ssh文件夹,用文本编辑器打开“id_rsa.pub”文件,复制内容到剪贴板。
6.2 打开 https://github.com/settings/ssh ,点击 Add SSH Key 按钮,粘贴进去保存即可。