1. Hue简述
Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job,执行Hive的SQL语句,浏览HBase数据库等等。
Hue在数据库方面,默认使用的是SQLite数据库来管理自身的数据,包括用户认证和授权,另外,可以自定义为MySQL数据库、Postgresql数据库、以及Oracle数据库。其自身的功能包含有:
- 对HDFS的访问,通过浏览器来查阅HDFS的数据。
- Hive编辑器:可以编写HQL和运行HQL脚本,以及查看运行结果等相关Hive功能。
- 提供Solr搜索应用,并对应相应的可视化数据视图以及DashBoard。
- 提供Impala的应用进行数据交互查询。
- 最新的版本集成了Spark编辑器和DashBoard
- 支持Pig编辑器,并能够运行编写的脚本任务。
- Oozie调度器,可以通过DashBoard来提交和监控Workflow、Coordinator以及Bundle。
- 支持HBase对数据的查询修改以及可视化。
- 支持对Metastore的浏览,可以访问Hive的元数据以及对应的HCatalog。
- 另外,还有对Job的支持,Sqoop,ZooKeeper以及DB(MySQL,SQLite,Oracle等)的支持。
http://shiyanjun.cn/archives/1002.html
2. Hue 进行 Hive查询以及检测
2.1 进入Hue
从CDH里面找到Hue并登陆
2.2 Hive的执行检测
在query edit的hive里面。可以看到。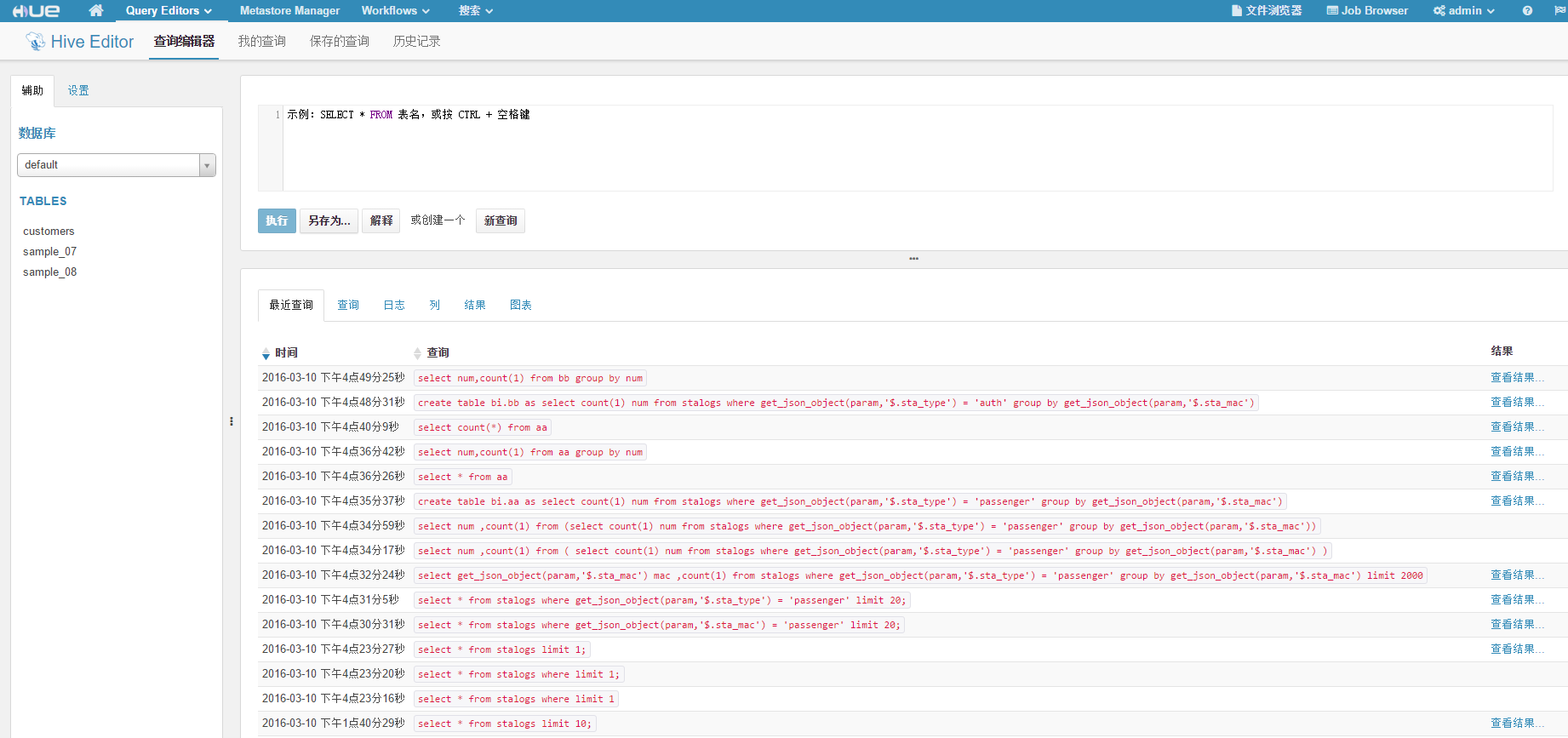
可以选择一个语句,并点击查看结果可以看到语句的执行结果,并且可以导出成文件形式。
如果查询结果不保存的话,集群重启之后之前的结果不保存。这个只能相当于一个Web UI的Hive。
2.3 Job Browser查询job状态
右上角可以查看job的各种状态。包括Succeeded、Running、Failed、Killed这4种状态。
如果想要看到Job具体执行状态信息,需要正确配置并启动Hadoop集群的JobHistoryServer和WebAppProxyServer服务,可以通过Web页面看到相关数据。
3. Hue的workflow设置
在Hue的主页里面有一个Workflow,点击之后有一个仪表盘以及一个编辑器。仪表盘可以检测目前的任务,编辑器是新建或者编辑工作流。
工作流可以自己设置mapreduce的jar包工作,或者hive的sql形式,也可以是spark形式。
如何使用jar提交可以参考这篇https://www.zybuluo.com/xtccc/note/272916