这是我在使用 HHsuite 工具包时的一些记录。
Update on 2020/12/16:
最近看到一些朋友访问到我这篇老文,自己已经不做 Bioinformatics 好多年,当时调试这些工具一直苦于没有任何教程,完全靠师兄只言片语的指导。自己鼓捣了很久才把工具调通,深感科研路上艰辛。希望这篇文章能够帮到你 Bioinformatics 的科研。
这是我在使用 HHsuite 工具包时的一些记录。
Update on 2020/12/16:
最近看到一些朋友访问到我这篇老文,自己已经不做 Bioinformatics 好多年,当时调试这些工具一直苦于没有任何教程,完全靠师兄只言片语的指导。自己鼓捣了很久才把工具调通,深感科研路上艰辛。希望这篇文章能够帮到你 Bioinformatics 的科研。
如果已经有一个足够强大的机器学习算法,为了获得更好的性能,最靠谱的方法之一是给这个算法以更多的数据。机器学习界甚至有个说法:“有时候胜出者并非有最好的算法,而是有更多的数据。”
但是现实中,人们已经花了很多精力进行手工标数据。如果算法能够从未标注数据中学习,那么我们就可以轻易地获取大量无标注数据,并从中学习。自学习和无监督特征学习就是这种的算法。尽管一个单一的未标注样本蕴含的信息比一个已标注的样本要少,但是如果能获取大量无标注数据(比如从互联网上下载随机的、无标注的图像、音频剪辑或者是文本),并且算法能够有效的利用它们,那么相比大规模的手工构建特征和标数据,算法将会取得更好的性能。
在自学习和无监督特征学习问题上,可以给算法以大量的未标注数据,学习出较好的特征描述。在尝试解决一个具体的分类问题时,可以基于这些学习出的特征描述和任意的(可能比较少的)已标注数据,使用有监督学习方法完成分类。
所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。
我们使用圆圈来表示神经网络的输入,标上“+1”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(下图中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。

这里使用的激活函数$f(\cdot)$是sigmoid函数。
使用$n_l$来表示网络的层数,上图的$n_l=3$,我们将第l层作为$L_l$,于是$L_l$是输入层,输出层是$L_{nl}$。上图的神经网络的参数是$(W,b) = (W^{(1)},b^{(1)},W^{(2)},b^{(2)})$,其中$W_{ij}^{(l)}$是第l层第j单元与第l+1层第i单元之间的联接参数(又叫权重),$b_i^{(l)}$是第l+1层第i单元的偏置项。注意,偏置单元是没有输入的,因为它们总是输出+1。同时使用$S_l$表示第l层的节点数(无偏置单元)。
我们用$ a^{(l)}_i $表示第 l 层第 i 单元的激活值(输出值)。当 l=1 时, $ a^{(1)}_i = x_i $,也就是第 i 个输入值(输入值的第 i 个特征)。对于给定参数集合 W,b ,我们的神经网络就可以按照函数 $h_{W,b}(x)$ 来计算输出结果。计算过程:
我们用 $z^{(l)}_i $表示第 l 层第 i 单元输入加权和(包括偏置单元),那么可以表示为 $z_i^{(2)} = \sum_{j=1}^n W^{(1)}_{ij} x_j + b^{(1)}_i $,则$ a^{(l)}_i = f(z^{(l)}_i) $。
这样我们就可以得到一种更简洁的表示法。这里我们将激活函数$ f(\cdot) $ 扩展为用向量(分量的形式)来表示,即 $ f([z_1, z_2, z_3]) = [f(z_1), f(z_2), f(z_3)] $ ,那么,上面的等式可以更简洁地表示为:
这个过程称作前向传播。使用$a^{(1)} = x $作为输入层的激活的值,那么给定第l层的激活值$a^{(l)}$之后,第l+1层的激活值$a^{(l+1)}$就可以按照步骤进行计算:
当然神经网络也可以有多个输出单元,以及多个隐藏层。
本文主要首先测试了pyspark读取hdfs文件进行word count应用,以及使用spark-shell同样进行了测试。
使用python编写spark应用并提交集群测试。
最后使用Spark进行SQL操作json文件。
Zigbee是IEEE 802.15.4协议的代名词。根据这个协议规定的技术是一种短距离、低功耗的无线通信技术。这一名称来源于蜜蜂的八字舞,由于蜜蜂(bee)是靠飞翔和“嗡嗡”(zig)地抖动翅膀的“舞蹈”来与同伴传递花粉所在方位信息,也就是说蜜蜂依靠这样的方式构成了群体中的通信网络。其特点是近距离、低复杂度、自组织、低功耗、低数据速率、低成本。主要适合用于自动控制和远程控制领域,可以嵌入各种设备。简而言之,ZigBee就是一种便宜的,低功耗的近距离无线组网通讯技术。
简单的说,ZigBee是一种高可靠的无线数传网络,类似于CDMA和GSM网络。ZigBee数传模块类似于移动网络基站。通讯距离从标准的75m到几百米、几公里,并且支持无限扩展。
ZigBee是一个由可多到65000个无线数传模块组成的一个无线数传网络平台,在整个网络范围内,每一个ZigBee网络数传模块之间可以相互通信,每个网络节点间的距离可以从标准的75m无限扩展。
与移动通信的CDMA网或GSM网不同的是,ZigBee网络主要是为工业现场自动化控制数据传输而建立,因而,它必须具有简单,使用方便,工作可靠,价格低的特点。而移动通信网主要是为语音通信而建立,每个基站价值一般都在百万元人民币以上,而每个ZigBee“基站”却不到1000元人民币。每个ZigBee网络节点不仅本身可以作为监控对象,例如其所连接的传感器直接进行数据采集和监控,还可以自动中转别的网络节点传过来的数据资料。除此之外,每一个Zigbee网络节点(FFD)还可在自己信号覆盖的范围内,和多个不承担网络信息中转任务的孤立的子节点(RFD)无线连接。
ZigBee自组织网的网状网通信实际上就是多通道通信,在实际工业现场,由于各种原因,往往并不能保证每一个ZigBee无线通道都能够始终畅通,就像城市的街道一样,可能因为车祸,道路维修等,使得某条道路的交通出现暂时中断,此时由于我们有多个通道,车辆(相当于我们的ZigBee控制数据)仍然可以通过其他道路到达目的地。而这一点对ZigBee工业现场控制而言则非常重要。
ZigBee自组织网采用的动态路由方式是指ZigBee网络中数据传输的路径并不是预先设定的,而是传输数据前,通过对网络当时可利用的所有路径进行搜索,分析它们的位置关系以及远近,然后选择其中的一条路径进行数据传输。在我们的网络管理软件中,路径的选择使用的是“梯度法”,即先选择路径最近的一条通道进行传输,如传不通,再使用另外一条稍远一点的通路进行传输,以此类推,直到数据送达目的地为止。在实际工业现场,预先确定的ZigBee传输路径随时都可能发生变化,或者因各种原因路径被中断了,或者过于繁忙不能进行及时传送。ZigBee动态路由结合网状网拓扑结构,就可以很好解决这个问题,从而保证数据的可靠传输。
为什么自组织网要采用动态路由的方式?
所谓动态路由是指网络中数据传输的路径并不是预先设定的,而是传输数据前,通过对网络当时可利用的所有路径进行搜索,分析它们的位置关系以及远近,然后选择其中的一条路径进行数据传输。在我们的网络管理软件中,路径的选择使用的是“梯度法”,即先选择路径最近的一条通道进行传输,如传不通,再使用另外一条稍远一点的通路进行传输,以此类推,直到数据送达目的地为止。在实际工业现场,预先确定的传输路径随时都可能发生变化,或者因各种原因路径被中断了,或者过于繁忙不能进行及时传送。动态路由结合网状拓扑结构,就可以很好解决这个问题,从而保证数据的可靠传输。
①低功耗。在低耗电待机模式下,2 节5 号干电池可支持1个节点工作6~24个月,甚至更长。这是ZigBee的突出优势。相比较,蓝牙能工作数周、WiFi可工作数小时。
②低成本。通过大幅简化协议(不到蓝牙的1/10) ,降低了对通信控制器的要求,按预测分析,以8051的8位微控制器测算,全功能的主节点需要32KB代码,子功能节点少至4KB代码,而且ZigBee免协议专利费。每块芯片的价格大约为2 美元。
③ 低速率。ZigBee工作在20~250 kbps的较低速率,分别提供250 kbps(2.4GHz)、40kbps (915 MHz)和20kbps(868 MHz) 的原始数据吞吐率,满足低速率传输数据的应用需求。
④近距离。传输范围一般介于10~100 m 之间,在增加RF 发射功率后,亦可增加到1~3 km。这指的是相邻节点间的距离。如果通过路由和节点间通信的接力,传输距离将可以更远。
⑤短时延。ZigBee的响应速度较快,一般从睡眠转入工作状态只需15 ms ,节点连接进入网络只需30 ms ,进一步节省了电能。相比较,蓝牙需要3~10 s、WiFi 需要3 s。
⑥高容量。ZigBee可采用星状、片状和网状网络结构,由一个主节点管理若干子节点,最多一个主节点可管理254 个子节点;同时主节点还可由上一层网络节点管理,最多可组成65000 个节点的大网。
⑦高安全。ZigBee提供了三级安全模式,包括无安全设定、使用接入控制清单(ACL) 防止非法获取数据以及采用高级加密标准(AES 128) 的对称密码,以灵活确定其安全属性。
⑧免执照频段。采用直接序列扩频在工业科学医疗( ISM) 频段,2. 4 GHz (全球) 、915 MHz(美国) 和868 MHz(欧洲) 。
ZigBee无线网络中一般包含三种类型的设备:
1. 协调器
2. 路由器
3. 终端设备
协调器负责启动整个网络。它也是网络的第一个设备。协调器选择一个信道和一个网络ID(也称之为PAN ID,即Personal Area Network ID),随后启动整个网络。协调器也可以用来协助建立网络中安全层和应用层的绑定(bindings)。在ZigBee网络中,路由器起着非常关键的作用。ZigBee自组织、自修复、拓扑网络结构等等无一不是通过路由来实现的,可以说,路由是ZigBee的灵魂。
注意:协调器的角色主要涉及网络的启动和配臵。一旦这些都完成后,协调器的工作就像一个路由器(或者消失go away)。由于ZigBee网络本身的分布特性,因此接下来整个网络的操作就不在依赖协调器是否存在。
路由器主要是允许其他设备加入网络,多跳路由和协助它自己的由电池供电的终端设备的通讯。通常,路由器希望是一直处于活动状态,因此它必须使用主电源供电。但是当使用树状网络拓扑结构时,允许路由间隔一定的周期操作一次,这样就可以使用电池给其供电。
终端设备是ZigBee实现低功耗的核心,它的入网过程和路由是一样的,和协调器、路由不一样,终端并不是时刻都处在接收状态的,大部分情况下,它都将处于IDLE或者低功耗休眠模式。它会定时同自己的父节点进行通信,询问是否有发给自己的消息,这个过程被形象地成为“心跳”。
ZigBee协议栈标准采用的OSI分层结构,其中物理层(PHY)、媒体接入层(MAC)和链路层(LLC)由IEEE802.15.4工作组制定,而网络层和应用层则由ZigBee联盟制定。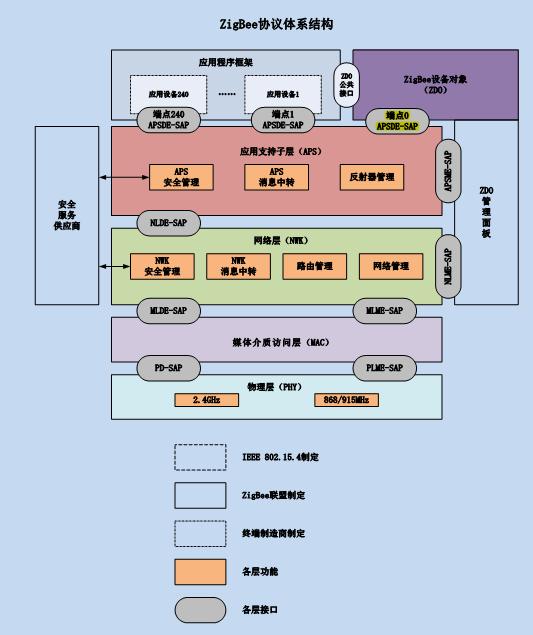
ZigBee的协议栈中,结构包含一系列的层,每一层通过使用下层提供的服务完成自己的功能并向上层提供服务。层与层之间通过服务访问点SAP进行连接。
IEEE 802.15.4 标准定义了两个物理层, 分别是 868 MHz/915 MHz 物理层和2.4 GHz物理层 , 两个物理层都使用相同的数据帧格式。868 MHz是欧洲的 ISM 频段, 它只有一个信道,传输速率为 20 kbps; 915 MHz 是美国的 ISM 频段, 它有 10 个信道, 传输速率为 40 kbps, 它们都采用 BPSK 调制方式。这两个频段的引入避免了与 2.4 GHz 附近各种无线通信设备的相互干扰,且这两个频段上的无线信号传播损耗较小,可以降低对接收机灵敏度的要求, 获得较远的有效通信距离,因而可以用较少的设备覆盖给定的区域。
2.4GHz是全球统一的无需申请的ISM频段, 对于 ZigBee 设备的推广和降低生产成本有极大的好处。 2.4 GHz 频段有 16 个信道, 能够提供 250 kbps 的传输速率, 它采用 O- QPSK 调制方式。
ZigBee的MAC子层主要从低成本、低复杂度和低功耗进行设计。功能包括设备间无线数据链路的建立与维护、确认模式的帧传送与接收、信道接入控制、帧校验、预留时隙管理、广播信息管理。LLC子层主要完成传输可靠性和控制、数据包的分段与重组、数据包的顺序
传输等功能。
数据链路层有4种帧类型: 数据帧、信标帧、命令
帧和确认帧, 其一般结构如下图所示。为了提高数据 传输的可靠性, ZigBee采用了载波侦听多址/ 冲突避免(CSMA/CA)的信道访问方式和完全握手协议。 该标准支持两种类型的地址, 一类是16位的局部地址, 处理起来更加方便, 节约功耗; 另一类是 64 位的扩展地址,可以为全球任意一个设备分配的唯一的地址。
ZigBee的网络层主要考虑采用基于Ad hoc技术的网络协议,使其在具有通用的网络层功能基础上能尽量的减小功耗、减少成本,并具有高度动态的拓扑结构和自组织、自维护的功能。网络层有二种帧类型:数据帧和命令帧,其一般结构如为了降低系统成本,ZigBee网络中定义了两种类型的设备:一种是全功能设备FFD( Full Function Device, FFD) 称为主设备,它承担了网络协调者的功能,可与网络中任何类型的设备通信,它亦可作为网络中的路由设备;另一种是简化功能设备RFD(Reduced Function Device,RFD)称为从设备,它不能作为网络协调者,只能与主设备通信。ZigBee主要采用了3种组网方式:星型网(Star)、网状型网(Mesh)和簇型网(Cluster tree), 如下图所示:
ZigBee应用层由三个部分组成:应用子层(APS)、ZDO(包含ZDO管理平台)和制造商定义的应用对象(App Obj)。APS通过网络层和安全服务提供层与端点的连接,并未数据传送、安全和绑定提供服务、可以适配不同但兼容的节点。
ZigBee路由成本为路由发现和维护管理提供了一种度量算法,是用来比较路由好坏的基础。路由开销是一条路径上的总的路由成本累加之和,假设经由一系列的节点[D1,D2……Dl]长度为L的路径P,它包含若干个子路段[Di,Di+1],那么这条长度为L的路径总成本为:
其中,$ C\{[D_i,D_{i+1}]\} $是链路成本,记为C(L)。它是链路的函数,取值集合为[0,……7]。该函数表达为:
其中pi是基于路径L链接成功实现数据转发的概率。路由开销反映了基于该链路正确转发一个数据包需要的重试次数。
ZigBee网络层采用一种基本的路由算法, 该算法的主要思想是先对接收的数据帧进行判断, 判断数据帧的来源。然后, 分解出数据帧中的目的地址, 根据目的地址, 采用相应的机制传送数据帧,具体如下图所示:
ZigBee的树形拓扑结构中,对于每个加入网络的节点,都有一个父节点与之对应,一个父节点有一个或者多个子节点,而一个子节点只能对应一个父节点,按照这样的排列形成一颗树,如果路由沿着这棵树进行,则就是Cluster-Tree算法。
在Cluster-Tree算法中,节点通过数据包中的目的节点的地址去计算下一跳,这样就不需要路由发现过程。假设某个FFD节点的地址是A,目的节点的地址是D,节点A向节点D传输数据,那么Cluster-Tree的流程如下:
1. 如果要传输的数据是传递给本身,那么就不需要转发给上层处理,否则转向2;
2. 如果待传输数据的目的节点是自己的邻居节点(路由表有路由信息),那么将数据直接发送给邻居节点,否则转3;
3. 判断并转发子节点或者父节点地址:
* 如果满足条件: $ A < D < A + Cskip(d - 1) $ 说明目的节点D是节点A的子节点,那么节点A就直接将数据发送给D,下一跳地址A’的根据如下公式进行计算:
如果不满足条件,则A将数据转发给父节点,由父节点沿着树去寻找目的节点。
当源节点是RFD的时候,首先源节点会把数据交给父节点缓存,然后由父节点寻找目的节点。
Cluster-Tree算法巧妙利用了各个网络节点获得的分配地址呈现树状结构的特性来选择路由,节点不用再内存中保留一个路由表,也不用去完成发现路径的操作,所以整个网络流量显著降低。
算法存在不足 :因为按照树形结构进行路由,所以很有可能不是最短路,比实际要长,会造成分组传输时延高。而且较少深度的节点(接近树根的节点),业务比较大,而对于接近叶子的节点,流量又很小,造成通信流量分配不均衡。
AODV算法是在传统的按需路由算法DSR和DSDV上发展而来,采用动态路由发现、维护机制和目的序列,以DSDV为基础,结合DSR的按需路由思想进行改进。
在AODV算法中,有三种控制分组:路由请求(RREQ)、路由应答(RREP)和路由错误(RRER),Hello消息是特殊的RRER分组。
当源节点需要与其他节点通信但是路由表没有到这个节点的路由时,它就向所有的邻居节点广播一个RREQ分组,各个邻居节点采用泛洪的方式在网络中传播RREQ。当中间其他节点收到这个RREQ时,首先判断是否收到相同源节点和目的节点的RREQ,如果是则丢弃;如果不是,就利用RREQ创建一个表项,但先不分配有效序号,只是记录一个临时的到达源节点的反向路径,目的是使RREQ分组能够返回源节点,并且中间节点每转发一次RREQ就讲跳数加1。如果中间节点含有到目的节点的路由,就按照RREQ经过的路径反向发送RREQ给源节点,否则继续广播该RREQ。
当目的节点收到RREQ同样建立反向路由,然后目的节点也沿着RREQ经过路径给源节点发送RREQ,收到RREQ的节点建立到目的节点的正向路径,这样源节点就可以根据收到的RREQ信息获得目的节点的路由并利用该路由向目的节点发送数据。当源节点移动时,它会重新发起路由发现算法。
算法存在不足 :
1. 跳数少并不是路径最优
2. 跳数少不意味着链路中节点最空闲
ZigBee是一种新兴的专为低速率无线个域网而设计的低成本、低功耗的短距离无线通信协议。由于ZigBee技术出现时间较晚,目前规范和应用仍然在不断发展中。
任秀丽, 于海斌. ZigBee 无线通信协议实现技术的研究[J],计算机工程与应用,2007,43(6).
因为我们是朋友,所以你可以使用我的文字,但请注明出处:http://alwa.info
本文主要进行实验Spark Streaming流式计算模型。
首先测试TCP连接的流式计算模型,
yum install nc
先安装这个,然后使用
nc -lk 9999
启动服务,后面直接朝这里输就能看到相应输出,这个是向localhost:9999发数据。
这个程序是进行spark的word count测试,输入的数据就是如上的tcp链接的输入数据。可以在spark-shell里输入如下代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
// Create a local StreamingContext with two working thread and batch interval of 1 second
val conf = new SparkConf().setMaster("local[4]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))
import org.apache.spark.streaming.StreamingContext._
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
注意 :可能会报initial失败的错误,可能是setMaster这边写错了,我这里是写的是local的开4核的意思。部署程序时一定要指定master的位置。
如果选择的部署模式是standalone且部署到你配置的这个集群上,可以指定MASTER=spark://node1:7070,依据你的spark集群,修改主机和端口号。
有几种方式可以进行指定Spark计算时候的Master。
通过spark shell,执行后进入交互界面1
MASTER=spark://IP:PORT ./bin/spark-shell
1 | val conf = new SparkConf() |
local 本地单线程
local[K] 本地多线程(指定K个内核)
local[*] 本地多线程(指定所有可用内核)
spark://HOST:PORT 连接到指定的 Spark standalone cluster master,需要指定端口。
mesos://HOST:PORT 连接到指定的 Mesos 集群,需要指定端口。
yarn-client客户端模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。
yarn-cluster集群模式 连接到 YARN 集群 。需要配置 HADOOP_CONF_DIR。
因为我们是朋友,所以你可以使用我的文字,但请注明出处:http://alwa.info
Spark最为重要的特性之一就是可以在多个操作(Action)之间,将一个或多个RDD关联的数据集(Dataset)以分区(Partition)为单位进行持久化(Persist)或缓存(Cache),存储介质通常是内存(Memory)。
RDD的全称是“Resilient Distributed Dataset”,即“弹性分布式数据集”,它是一个可以并行操作的具有容错性的元素集。有两种方法可以创建RDD:一个存在scala的驱动程序(即spark程序),或者引用一个外部存储系统(例如共享文件系统、HDFS、Hbase,或其他任何支持hadoop输入格式的数据源)中的数据集。用户可以使用RDD在内存,在并行运算中有效地重复利用。如果节点挂掉,RDD可以自动恢复。
编写Spark应用与之前实现在Hadoop上的其他数据流语言类似。代码写入一个惰性求值的驱动程序(driver program)中,通过一个动作(action),驱动代码被分发到集群上,由各个RDD分区上的worker来执行。然后结果会被发送回驱动程序进行聚合或编译。本质上,驱动程序创建一个或多个RDD,调用操作来转换RDD,然后调用动作处理被转换后的RDD。
这些步骤大体如下:
.
当Spark在一个worker上运行闭包时,闭包中用到的所有变量都会被拷贝到节点上,但是由闭包的局部作用域来维护。Spark提供了两种类型的共享变量,这些变量可以按照限定的方式被所有worker访问。广播变量会被分发给所有worker,但是是只读的。累加器这种变量,worker可以使用关联操作来“加”,通常用作计数器。
Spark应用本质上通过转换和动作来控制RDD。
简略描述下Spark的执行。本质上,Spark应用作为独立的进程运行,由驱动程序中的SparkContext协调。这个context将会连接到一些集群管理者(如YARN),这些管理者分配系统资源。集群上的每个worker由执行者(executor)管理,执行者反过来由SparkContext管理。执行者管理计算、存储,还有每台机器上的缓存。
重点要记住的是应用代码由驱动程序发送给执行者,执行者指定context和要运行的任务。执行者与驱动程序通信进行数据分享或者交互。驱动程序是Spark作业的主要参与者,因此需要与集群处于相同的网络。这与Hadoop代码不同,Hadoop中你可以在任意位置提交作业给JobTracker,JobTracker处理集群上的执行。
yarn需要submit提交到集群:https://spark.apache.org/docs/1.2.0/submitting-applications.html#master-urls
spark1.0起的版本在提交程序到集群有很大的不同,需要注意:1
2
3
4
5
6
7./bin/spark-submit \
--class <main-class>
--master <master-url> \
--deploy-mode <deploy-mode> \
... # other options
<application-jar> \
[application-arguments]
例如:
Run application locally on 8 cores1
2
3
4
5./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \
100
Run on a Spark standalone cluster1
2
3
4
5
6
7./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
Run on a YARN cluster1
2
3
4
5
6
7
8export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn-cluster \ # can also be `yarn-client` for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
Run a Python application on a cluster1
2
3
4./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
Spark编程指导:http://www.kinelf.com/?p=217
因为我们是朋友,所以你可以使用我的文字,但请注明出处:http://alwa.info
装好spark之后,直接从pyspark是可以直接进入python的spark客户端的,命令行下。
但是如果要写python的程序的话直接import pyspark还是不行,提示ImportError: No module named pyspark。
修改~/.bashrc,把Path修改了,可以先看$SPARK_HOME和$PYTHONPATH是不是已经对了,然后去Spark的安装目录下看下路径和具体的文件是不是,修改bashrc文件。1
2
3export SPARK_HOME=/opt/cloudera/parcels/CDH-5.6.0-1.cdh5.6.0.p0.45/lib/spark
export PYTHONPATH=/usr/local/bin/python2.7
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.8.2.1-src.zip:$PYTHONPATH
最后运行
source .bashrc
使用spark-submit提交脚本。
CDH有python配置,可以配置python的路径,暂时还不清楚这个的意思是什么?这个CDH页面里的配置会修改spark的conf文件里的pythonpath。
上面的配置是配的全局的配置。