本文介绍了AutoEncoder。包括如下内容:
- AutoEncoder的定义和推导。
- Sparse AutoEncoder由来和介绍。
- 做Deep Learning所用的unsupervised learning的方法之间的比较。
1. 数学基础
1.1 Orthogonal Matrix
满足如下定义的是Orthogonal Matrix
以元素表示为。
1.2 The theorem about SVD
假设A是任意一个矩阵,SVD表示就是$A = U \Sigma V^T $。
其中 $\Sigma$ 是一个对角矩阵。
$U, V$都是orthonormal矩阵(columns/rows are orthonormal vectors)。
假设$U_{. ,\le k} \Sigma _{_{\le k ,\le k}} V_{. ,\le k}^T $作为当我们只保留最大的k个singular values的decomposition。
这样矩阵B,秩为k,它与A的距离就可以写一个式子。
求得$B^{*} = U_{. ,\le k} \Sigma _{_{\le k ,\le k}} V_{. ,\le k}^T$。
这个定理需要用在推导过程中,具体看参考文献[3]。
2. AutoEncoder 定义
AutoEncoder 是多层神经网络,其中输入层和输出层表示相同的含义,具有相同的节点数。AutoEncode学习的是一个输入输出相同的“恒等函数”。不过输入和输出相同,使得这个网络的输出没有任何意义。AutoEncoder的意义在于学习的(通常是节点数更少的)中间coder层(最中间的那一层),这一层是输入向量的良好表示。这个过程起到了“降维”的作用。当AutoEncoder只有一个隐含层的时候,其原理相当于主成分分析(PCA),当AutoEncoder有多个隐含层的时候,每两层之间可以用RBM来pre-training,最后由BP来调整最终权值。网络权重更新公式很容易用求偏导数的方法推导出来,算法是梯度下降法。(RBM:层内无连接,层间全连接,二分图)。
当AutoEncoder只有一个隐含层的时候,其原理相当于主成分分析(PCA)。但是 AutoEncoder 明显比PCA的效果更好一点,尤其在图像上。 当AutoEncoder有多个隐含层的时候,每两层之间可以用RBM来pre-training,最后由BP来调整最终权值。
通过unsupervised learning只对input$X^{(t)}$我们可以做下面的事情:
- 自动获取有意义Features
- leverage无标注数据
- 添加一个有数据驱动的规则化工具来帮助训练(add a data-dependent regularizer to trainings)
下图是一个AutoEncoder的三层模型,Input layer,Hidden layer,和Output layer。其中$W^{*} = W^T$,因为使用tied weight。

如果是实数值作为输入,我们要优化的目标函数是:
如果是01值那么就是:
loss function的梯度可以写成:
当然使用tied weight,那么是两个$\nabla$的和。
具体推导在参考文献[3],而且目前只能做有关liner AutoEncoder的推导,其他的目前是NP问题。
3. Denoising AutoEncoder
按照常理,hidden layer压缩输入,而且是一句training集的分布。hidden layer比Input layer小称之为 undercomplete representation。
overcomplete representation 就是反过来,hidden layer比Input layer要大。这个会导致无法保证hidden layer提取有用的结构信息。
下图是形成的网络结构:
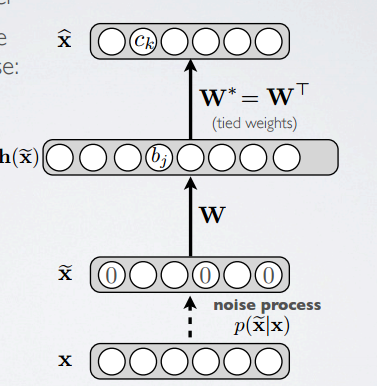
Denoising AutoEncoder是AutoEncoder的一个变种,与AutoEncoder不同的是,Denoising AutoEncoder在输入的过程中加入了噪声信息,从而让AutoEncoder能够学习这种噪声。直观可见就是新的输入层有些值变成0了。
意思就是要使得我们的表达能够足够强壮,所以我们加入噪声信息。
(一) 随机让一些input值做为0,根据一个概率v。
(二) 加入Gaussian噪声。
具体会重新构建$\hat{X}$使用改变过的输入$\tilde{X}$,并且loss function是使用noiseless input X。我们把noise process称为$p(\tilde{X}|X)$。
YouTube上有视频讲的很清楚,地址。
4. Sparse Autoencoder
这个部分在我之前的博文里有讲到,自编码算法与稀疏性 自我学习。
5. 几种方法不同点
首先Autoencoder和RBM是一类的,都属于学习模型;而稀疏编码更像是施加在这些基本模型上的一种优化手段。
Autoencoder和RBM的不同之处:Autoencoder的神经元是确定型的,用的是sigmold函数,就像传统的ff网络一样。而RBM的神经元是随机的。(最基本的RBM神经元只有0和1两种状态,但是扩展后可以在这个区间上取任何值)由于autoencoder的确定性,它可以用BP方法来训练。但是RBM就只能用采样的方法来得到一个服从RBM所表示分布的随机样本。(Gibbs采样,CD采样等等)在深度学习里面,可以把autoencoder和RBM都看作是一块块砖头,我们可以用许多这样的砖头构造出深层次的网络。基本思路是前面先用这些“砖头”搭出几层网络,自动学习出数据的一些特征后,后面再用一个分类器来分类,得到最后的结果。如果用autoencoder作砖头,得到的就是stacked autoencoder;如果用RBM作砖头,得到的就是deep belief network。
Denoising AutoEncoder与RBM非常像,:
(1)参数一样:隐含层偏置、显示层偏置、网络权重
(2)作用一样:都是输入的另一种(压缩)表示
(3)过程类似:都有reconstruct,并且都是reconstruct与input的差别,越小越好
Denoising AutoEncoder与RBM的区别:RBM是能量函数,区别在于训练准则。RBM是隐含层“产生”显示层的概率(通常用log表示),Denoising AutoEncoder是输入分布与reconstruct分布的KL距离。所用的训练方法,前者是CD-k,后者是梯度下降。RBM固定只有两层;AutoEncoder,可以有多层,并且这些多层网络可以由标准的bp算法来更新网络权重和偏置,与标准神经网络不同的是,AutoEncoder的输入层和最终的输出层是“同一层”,不仅仅是节点数目、输出相同,而是完完全全的“同一层”,这也会影响到这一层相关的权值更新方式。总之,输入与输出是同一层,在此基础上,再由输入与输出的差别构造准则函数,再求各个参数的偏导数,再用bp方式更新各个权重。
再说稀疏编码,它是把大多数的神经元限制为0,只允许少量的神经元激活,来达到“稀疏”的效果。这主要是为了模拟人眼视觉细胞的特性。在算法里,其实就是在用来优化的目标函数里面加入一个表示稀疏的正则项,一般可以通过L1范数或者KL divergence来实现。并且稀疏性可以加到autoencoder上,也可以加到RBM上。稀疏编码是训练整个深层神经网络的一种预先训练的方法。它是一个非监督学习的过程,通过神经元对feature本身作一次回归,可以得到一个神经元的初始参数。这些参数对再下来的监督学习过程算是个初始化。这一步也可以用分层的监督学习来取代。
参考文献
[1] 维基百科:https://en.wikipedia.org/wiki/Autoencoder
[2] AutoEncoder:http://jacoxu.com/?p=1108
[3] 数学推导AutoEncoder Optimality:https://dl.dropboxusercontent.com/u/19557502/6_04_linear_autoencoder.pdf
[4] 知乎上回答地比较好的比较AutoEncoder和RBM联系区别的回答:https://www.zhihu.com/question/22906027/answer/40628698
因为我们是朋友,所以你可以使用我的文字,但请注明出处:http://alwa.info